环境空气质量监测数据是公众了解空气质量最重要的依据,被广泛应用于改进空气质量预报、污染过程分析等众多大气污染相关研究。但由于仪器故障、恶劣环境和测量方法等原因,异常数据时有出现。
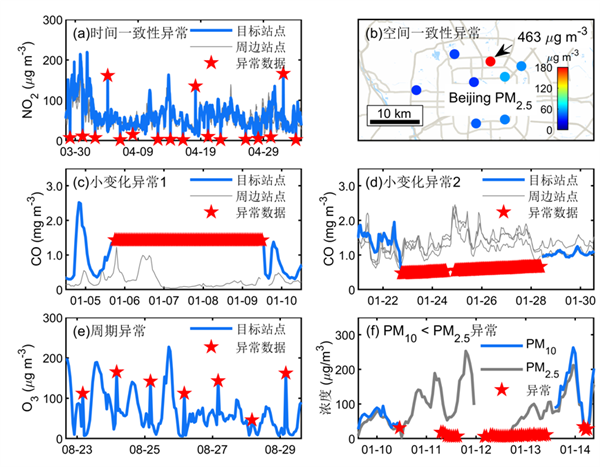
图1 空气质量监测数据中的典型异常示例
实际应用中通常依赖人工审核识别异常数据,但随着监测站数量的快速增加,人工审核工作量大幅增加,无法满足海量监测数据准实时应用(如准实时同化等)的需求。
针对于此,中国科学院大气物理研究所吴煌坚博士和唐晓副研究员等提出了一套基于残差概率的自动化异常识别方法。该方法使用低通滤波、空间回归等方式拟合监测数据,通过拟合残差的分布特征计算残差概率,进而设计程序自动识别并剔除小概率的异常数据。研究结果表明,引入残差概率可以将多项异常检查有机结合。例如通过假设时间残差和空间残差服从二元正态分布,可以将监测数据的时间一致性和空间一致性协同考虑,更准确地识别异常数据。
该方法可以以准实时方式(1分钟内)对全国1436个国控站点六项常规污染物(PM2.5, PM10, SO2, NO2, CO, O3)监测中的可疑异常数据进行标记和识别。目前该方法已被应用于中国环境监测总站的空气质量预报系统,并计划应用于实时的空气质量监测数据发布系统,为海量监测数据的快速应用提供技术支撑。
该研究已被《大气科学进展》接收并出版。
论文信息:
Wu, H. J., X. Tang, Z. F. Wang, L. Wu, M. M. Lu, L. F. Wei, and J. Zhu, 2018: Probabilistic automatic outlier detection for surface air quality measurements from the China National Environmental Monitoring Network. Adv. Atmos. Sci., 35(12), 1522–1532,http://doi.org/10.1007/s00376-018-8067-9 .



